Основы Smart Monitor Language (SML)
Smart Monitor Language (SML) — специализированный язык запросов платформы Smart Monitor, предназначенный для поиска, обработки и анализа машинных данных.
SML позволяет описывать аналитические запросы в виде последовательности команд, объединенных в единый конвейер обработки данных. Такой подход обеспечивает наглядность запросов, повторное использование аналитических сценариев и единый способ работы с различными источниками данных.
Цель данной статьи — дать обзор синтаксиса Smart Monitor Language и основных принципов работы с ним, а также показать, как писать корректные и оптимизированные SML-запросы. В статье рассматриваются базовые конструкции языка, типовые команды и шаблоны запросов, распространенные сценарии использования, а также практические рекомендации по повышению производительности и избеганию типичных ошибок.
Архитектурная модель и принципы работы SML
Smart Monitor Language построен на конвейерной (pipeline) модели обработки данных. Запрос в SML представляет собой последовательность команд, разделенных символом вертикальной черты (|), где каждая команда принимает на вход набор событий и передает результат своей обработки следующей команде. Такая архитектура обеспечивает декларативное описание аналитических сценариев и позволяет комбинировать операции поиска, фильтрации, преобразования и агрегации данных в одном запросе.
Структура команды SML
Каждая команда в SML имеет строгую структуру: имя операции, за которой следуют ее аргументы и/или параметры.
Общий шаблон команды
<command> [positional arguments] [parameters] [clauses/expressions]
Ключевые элементы:
-
command— имя операции (source,search,peval,aggs,joinи т.д.) -
позиционные аргументы (
positional arguments) — обязательные или опциональные значения, идущие сразу за именем команды.
Пример:source nginx-1— здесь имя источникаnginx-1является позиционным аргументом -
именованные параметры (
parameters) — настройки в форматеkey=value, определяющие поведение команды.
Пример:source nginx-1 qsize=5000— параметрqsizeограничивает объем выборки -
ключевые слова и предложения (
clauses) — специфические для конкретных команд синтаксические конструкции.
Пример:byвaggs count by field,onвjoin ... on a=b,spanвtimeaggs span=1h -
выражения (
expressions) — логические условия или математические формулы.
Пример:search status >= 500в командеsearchилиcount * 100вeval -
подзапросы — вложенные конвейеры, заключаемые в квадратные скобки
[...]. Используются в командах сопоставления данных, таких какjoinилиappend
Правила записи и типы данных
Для корректной интерпретации запроса аналитическим движком SME (Smart Monitor Engine) необходимо соблюдать следующие правила:
-
Строковые значения, содержащие пробелы или спецсимволы, необходимо заключать в одинарные (
' ') или двойные (" ") кавычки. В остальных случаях кавычки необязательны -
Числовые значения (
100,0.5) и булевы константы (true,false) записываются без кавычек -
Для обращения ко вложенным структурам используется «точечная» нотация (например,
user.agent.browser) -
Имена команд регистронезависимы, однако рекомендуется придерживаться нижнего регистра для единообразия текста запроса
Базовый синтаксис и структура запроса
Любой запрос в SML строится по строгим правилам, которые определяют, как данные будут извлекаться и обрабатываться. Понимание структуры запроса помогает избегать синтаксических ошибок и писать читаемый текст запроса.
Структура запроса
Запрос всегда начинается с определения источника данных (команда генерации или загрузки), за которой следует цепочка пайплайнов.
Структура типового запроса на SML представлена ниже:
source log-index qsize=5000 /* 1. Загрузка данных */
| search log_level="error" /* 2. Фильтрация */
| peval host=lower(host) /* 3. Трансформация/Вычисление */
| aggs count by host /* 4. Агрегация */
Данный запрос загружает данные из источника log-index, фильтрует ошибки, приводит значение поля host к нижнему регистру и выполняет агрегацию количества событий по каждому хосту.
В Smart Monitor нет строгого требования создавать новый пайплайн (|) для каждой команды одного типа (например, в peval допускается множественное вычисление значений, перечисленных через запятую), однако для лучшей читаемости запроса рекомендуется выносить каждую команду на отдельную строку.
Комментарии
SML поддерживает многострочные комментарии в стиле языка программирования C. Они игнорируются при выполнении запроса и крайне полезны для документирования сложной логики.
/* Этот блок фильтрует только успешные запросы
и агрегирует количество событий по коду ответа
*/
| search status < 400
| aggs count by status
Источники данных
Smart Monitor, благодаря концепции Search Anywhere, позволяет выполнять поиск в различных источниках. В настоящий момент поддерживается четыре типа хранилищ:
- OpenSearch
- Elasticsearch,
- ClickHouse
- Hadoop
Независимо от того, используется ли поисковое, аналитическое или распределенное хранилище, базовая структура SML-запроса остается неизменной. Это позволяет переносить аналитические сценарии между источниками данных без изменения общей логики запроса.
Для выгрузки из OpenSearch и Elasticsearch используется команда source, после которой следует название индекса или паттерн индекса, например:
source employee_list-0073
source employee_list
Для получения данных из ClickHouse используется команда clicksource или source. Обращение к данным происходит по схеме db_name.table_name, например:
clicksource 'hr.employee_list'
| search status="Уволен"
Для выгрузки из Hadoop используется команда hdhsource или source. Схема обращения к данным аналогична ClickHouse:
hdhsource 'hr.employee_list'
| search status="Уволен"
При работе с OpenSearch Smart Monitor позволяет объединять данные из нескольких источников в одном запросе. Режим объединения данных при запросе к нескольким источникам настраивается опциональным параметром append после команды source:
source sm_cs_iam_indexes, sm_servers_indexes append = true
При необходимости экранирования спецсимволов в названии источника можно использовать одинарные кавычки, например:
source '*-antifraud-event-*'
Символ * в имени источника работает как маска и позволяет запросить сразу несколько индексов. Например:
sm-sml source .smos_internal-*
Этот запрос вернет данные из всех индексов вида .smos_internal-2026.12, .smos_internal-2026.13 и т. д.
Подробнее с командой source можно ознакомиться в статье документации.
После указания источника данных выполняется поиск, фильтрация и агрегация данных.
Работа со справочниками
В Smart Monitor предусмотрен механизм использования справочников (lookup), который помимо обогащения событий дополнительной информацией других источников может быть использован и в качестве самостоятельного источника данных.
Для загрузки данных из справочника в SML используется команда inputlookup. Она позволяет считать содержимое справочника и включить его в конвейер обработки данных.
Пример загрузки и использования данных из справочника:
| inputlookup whitelist_lookup
| aggs count(user_ip) as ip
Генерация тестовых данных
Команда makeresults используется для создания искусственного набора событий непосредственно в SML-запросе, без обращения ко внешним источникам данных. Она формирует одно или несколько пустых событий, которые затем могут быть дополнены полями с помощью команд вычисления и преобразования.
| makeresults
| eval numbers = {"5", "9", "7"}
| stats max(numbers) as maximum
Данный пример вернет максимальное число из multivalue-поля numbers.
Временные параметры
Результат поиска в Smart Monitor агрегируется по временному интервалу, указанному в фильтре на странице поиска, или в параметрах earliest и latest команды source. Результаты сортируются по убыванию значения временной метки. На основе полученных данных строится гистограмма за указанный период.
Гистограмма отображается только в том случае, если для индекса настроен шаблон. Если шаблон индекса не настроен, но существует необходимость получить распределенные по времени события, то непосредственно после source необходимо явно указать имя поля с временной меткой — с помощью аргумента timefield, например:
source nginx-logs-* timefield=@timestamp
| timeaggs count
Если поле временной метки не указано и шаблон не настроен, Smart Monitor выведет количество найденных документов, однако сами события отображаться не будут. Например, запрос source .smos_incident-* покажет N документов было найдено, но список событий останется пустым. Чтобы события отобразились, необходимо указать корректное поле времени: source .smos_incident-* timefield=search_params.earliest_time.
Пример выполнения поискового запроса и построения гистограммы приведен на изображении ниже.

Подробные сведения о работе с временными диапазонами в Smart Monitor содержится в соответствующем разделе документации.
Параметр qsize
Важным параметром, часто используемым при выполнении поисковых запросов, является параметр qsize, который ограничивает объем данных, обрабатываемых в памяти при выполнении запроса. Например, запрос SML следующего вида:
source internal_audit-* qsize=2000
ограничит результат поиска первыми 2000 событиями.
Изменение параметра qsize в большую сторону повышает нагрузку на систему, в частности, увеличивается потребление оперативной памяти.
Уровни выполнения команд в Smart Monitor
По уровню выполнения команды в Smart Monitor разделяются на две основные группы:
-
Команды, выполняющие операции над данными с помощью внутренних механизмов хранилища
-
Команды, выполняемые «в памяти» с помощью аналитического движка для обработки данных SME (Smart Monitor Engine)
Первый тип команд имеет преимущество над вторым в скорости выполнения ввиду использования внутренних механизмов хранилища. Однако, их применение ограничено: такие команды допустимы в запросе, если до них в конвейере находятся только команды выгрузки данных из источников и отсутствуют команды, выполняемые "в памяти". К таковым относятся source, search, peval, timeaggs и aggs.
При использовании команд, выполняемых "в памяти", результаты запроса ограничиваются первой тысячей. Увеличить объем обрабатываемых данных можно, настроив параметр qsize для команды source.
Особенности построения запросов для типов данных text и keyword
В источниках данных OpenSearch и Elasticsearch строковые поля часто индексируются двумя способами одновременно. Это называется механизмом мультиполей (multi-fields). Для эффективной работы в SML важно различать их назначение.
| Тип поля | Механизм обработки | Рекомендуемое использование в SML |
|---|---|---|
text (базовое поле) | Разбивается на отдельные токены (слова). | Полнотекстовый поиск, поиск подстрок и частичных совпадений. |
keyword (суффикс .keyword) | Хранится как единая неразрывная строка. | Точное совпадение, агрегация, группировка. |
Выбор между базовым именем поля и его версией с суффиксом .keyword напрямую определяет строгость фильтрации данных при использовании команды search. Помимо этого, поля .keyword создают меньшую нагрузку на поиск: в отличие от text, они не проходят полнотекстовый анализ и обрабатываются как единая строка.
Если поле уже определено в маппинге с типом keyword, добавлять суффикс .keyword не нужно — такого под-поля не существует, и запрос вернет пустой результат или ошибку. Суффикс .keyword актуален только для полей типа text, у которых есть мультиполе.
К примеру, запрос следующего вида вернет документы, содержащие слово memory в поле event.original:
source linux-logs-*
| search event.original="memory"
В то же время следующий запрос вернет документы, у которых поле event.original содержит только слово memory и ничего больше:
source linux-logs-*
| search event.original.keyword="memory"
Макросы
Макросы — многократно используемые фрагменты SML-запроса, которые позволяют упростить написание сложных запросов и стандартизировать аналитическую логику. В случаях, когда часто приходится использовать одно и то же длинное выражение или сложный фильтр, их можно сохранить как макрос и вызывать по короткому имени.
Для вставки макроса в запрос используется символ обратной кавычки (обратный апостроф — `). При выполнении запроса Smart Monitor автоматически заменяет имя макроса на его полное содержимое.
source nginx-*
| `filter_errors` /* Вызов макроса, содержащего логику фильтрации */
| aggs count by host
Фильтрация и логические условия
search
Команда search в SML применяется для поиска и фильтрации данных. Условия поиска задаются по схеме field=value.
Пример выполнения поиска:
source internal_audit-*
| search log_level="info"
SML поддерживает операторы AND, OR, NOT. По умолчанию между условиями в search действует оператор AND.
Язык запросов Smart Monitor поддерживает применение Wildcards. Для таких команд, как eval, where, like применяется символ %. Для команды search используется символ *. Также поддерживаются поиск по регулярному выражению через regex и поиск по маске подсети (cidr).
Помимо поиска по полям в Smart Monitor также доступен полнотекстовый поиск. К примеру, запрос:
source internal_audit-*
| search "warning"
Выполнит поиск ключевого слова warning по всем полям всех документов индекса internal_audit-*.
Префикс ~ перед кавычками (~"фраза") ищет отдельные слова без полного совпадения. К примеру, следующий запрос:
source internal_audit-*
| search ~"getting access"
Выполнит поиск всех документов, содержащих слова getting и/или access в любом из текстовых полей документов.
Подробнее с механизмом полнотекстового поиска в Smart Monitor можно ознакомиться в отдельной статье документации.
where
Команда where также применяется для фильтрации данных в поисковых запросах. Условия пишутся в формате сравнения в стиле большинства языков программирования, например, where count>5 или where user=="admin".
В SML для where используется двойное равенство == в отличие от одиночного = в search.
Команда where поддерживает такие функции, как like(), match(), cidrmatch(), in() и др.
Приоритет операторов
В search оператор AND выполняется раньше OR, в where — наоборот, поэтому для сложных условий рекомендуется использовать скобки, например:
| search host="mail" AND NOT (code="4625" OR code="4624")
Операторы сравнения и кавычки
SML поддерживает стандартные операторы: =, !=, <, >, <=, >=. При сравнении чисел работает обычная арифметика, при сравнении строк — полное совпадение значения. Для поиска части подстроки в поисковом запросе следует использовать wildcard-символы. Поисковые значения обязательно необходимо заключать в двойные кавычки ("), если в них есть разделители или специальные символы. Обратный слеш (\) в поисковых запросах необходимо экранировать вторым обратным слешем, например:
| search app_path="C:\\Windows\\cmd.exe"
Детальная информация о построении выражений в запросах SML содержится в специальном разделе документации Выражения.
Агрегация и статистика
aggs и stats
В Smart Monitor для выполнения агрегирующих вычислений используются две команды: aggs и stats. Команда aggs, будучи командой, выполняющей операции над данными с помощью внутренних механизмов хранилища, имеет преимущество над stats в скорости работы и объеме обрабатываемых данных. aggs имеет большинство функций, реализованных в stats, включая математические операции (max, min, sum, perc), операции для работы с массивами данных (count, values, earliest) и другие функции. При необходимости обработать неограниченное количество уникальных значений можно использовать параметр composite=true.
timeaggs и timechart
Команды timechart и timeaggs в Smart Monitor выполняют одну и ту же функцию — агрегацию данных по времени. Аналогично командам aggs и stats данные команды выполняются на разных уровнях - timeaggs на уровне хранилища, а timechart в памяти, поэтому timeaggs выполняется быстрее и предпочтительнее в большинстве сценариев. Команда timeaggs имеет аналогичный с timechart функционал и включает в себя такие обязательный функции, как count, avg, dc и др., а также некоторые опциональные аргументы (span, timefield, limit, и т.д.).
eventstats и streamstats
Smart Monitor для выполнения статистических операций также предоставляет команды eventstats и streamstats. Если eventstats cохраняет результаты в новом поле, то streamstats работает с данными в потоковом.
Преобразование и вычисление полей
peval и eval
Команда peval является аналогом команды eval, но работает с помощью внутренних механизмов хранилища.
eval в Smart Monitor реализует большое число функций для преобразования и вычисления данных, включая работу с временными, криптографическими, математическими и прочими операциями.
Пример использования команд peval/eval:
| peval agent = agent.keyword + port
В приведенном примере будет создано новое поле agent как конкатенация полей agent.keyword и port.
Важной особенностью команды eval в SML является невозможность использования команды в статистических выражениях, как, например, | stats count(eval(status="404")) AS error_count. В Smart Monitor команды peval и eval являются самостоятельными и не могут встраиваться как аргументы в другие команды — за исключением подзапросов в квадратных скобках [...].
Прочие команды обработки
Помимо перечисленных, в Smart Monitor реализованы и другие команды обработки данных. Среди таких, например, следующие команды:
-
fields– оставляет/исключает поля -
dedup– удаляет дубликаты по полям -
sort- выполняет сортировку данных -
head- возвращает N первых результатов запроса -
mvexpand– развертывает multivalue-поля в несколько событий -
rename– переименовывает поля
Оптимизация запросов SML
Производительность SML-запросов в Smart Monitor во многом определяется порядком команд и объемом данных, обрабатываемых на каждом этапе конвейера. Основным принципом оптимизации является максимально ранняя фильтрация данных — условия поиска следует задавать сразу после указания источника, чтобы сократить количество событий до выполнения последующих операций.
Вторым важным фактором оптимизации запросов является использование команд, выполняемых на уровне хранилища (search, peval, aggs и timeaggs), так как они задействуют внутренние механизмы источника данных и работают значительно быстрее, чем команды, выполняемые в памяти аналитического движка. Это особенно важно при агрегациях и работе с большими объемами данных.
Подробные рекомендации и примеры оптимизации SML-запросов приведены в статье Советы по оптимизации SML.
Диагностика и отладка
Эффективное использование Smart Monitor Language предполагает владение инструментами диагностики и методами отладки запросов, которые позволяют локализовать ошибки в цепочках пайплайнов и минимизировать избыточную нагрузку на ресурсы платформы.
Типичные ошибки в SML-запросах
При выполнении запросов в Smart Monitor могут возникать ошибки на разных уровнях: синтаксическом (парсинг запроса), семантическом (логика условий) или производительном (ресурсы системы).
Синтаксические ошибки
- Отсутствие вертикальной черты (
|) для новой команды
Пример:
source winevents
search agent.id = "5436647"
- Незакрытые скобки в запросе. В случаях, если в запросе открыта, но не закрыта скобка, возникнет синтаксическая ошибка
Пример:
source sm_users
| peval user.name=mvindex(split(user.name, "@", 0)
- Неправильное использование кавычек или спецсимволов. Строки с пробелами или спецсимволами должны быть в кавычках (
" "или' '). Обратный слеш (\) требует экранирования (\\).
source *-internal*
| search user_name = Иван Иванов
- Опечатки в именах команд или параметров
Семантические ошибки
- Использование неверного оператора сравнения. Наиболее частая ошибка — применение оператора
=в командеwhere
| where status = 500
- Неверные ожидания от полнотекстового поиска. Использование команды
searchбез указания поля выполняет полнотекстовый поиск по всем текстовым полям, что может приводить к большому количеству нерелевантных результатов
| search "error"
В большинстве случаев предпочтительнее явно указывать поле поиска.
Ошибки, связанные с типами данных
Ошибки данного класса возникают при некорректном использовании типов полей, особенно при работе с OpenSearch и Elasticsearch.
- Агрегация по полям типа text
Поля типа text предназначены для полнотекстового поиска и не подходят для агрегаций.
При этом такой подход оправдан только для полей с ограниченным набором значений (статус, тип, хост и т.д.). Поля вроде message или event.original, содержащие произвольный текст, лучше разбивать на конкретные поля на уровне парсера — агрегация по ним через .keyword может привести к проблемам с производительностью.
| aggs count by message
Для агрегаций следует использовать поле с суффиксом .keyword.
- Сравнение строк и чисел без приведения типов
Сравнение строковых значений с числовыми условиями может приводить к некорректным результатам или пустой выборке.
Ошибки, связанные с моделью выполнения команд
Smart Monitor выполняет команды на разных уровнях — на уровне хранилища или в памяти аналитического движка. Нарушение последовательности применения команд разного уровня выполнения приводит к ошибкам и некорректным результатам.
- Использование команд уровня хранилища после команд в памяти
Если перед командой уровня хранилища используется команда, работающая в памяти, операция не будет выполнена:
| eval host_lc = lower(host)
| aggs count by host_lc
В данном случае использование команды eval исключает использование команды aggs, работающей на уровне хранилища. Оптимальный вариант — применение peval вместо eval. Альтернативный, но не лучший вариант — использование stats после eval.
- Проблемы с ограничением объема данных
При использовании команд в памяти результаты запроса по умолчанию ограничиваются первой тысячей событий, если в запросе явно не указан параметр qsize.
Ошибки из-за деградации производительности
При выполнении тяжелых запросов с чрезмерно завышенным значением возвращаемых документов в параметре qsize и сложными агрегациями могут возникнуть следующие ошибки:
-
Failed to execute phase [fetch]— ошибка на этапе получения документов из шардов OpenSearch/Elasticsearch при попытке загрузить в память большое число результатов -
Command RAM limit exceeded— запрос превысил допустимый лимит оперативной памяти для выполнения -
Request failed with status code 502— ошибка шлюза, может означать, что сервер не успел обработать тяжелый запрос или соединение было разорвано из-за перегрузки или таймаута -
Search cancelled - превышение таймаута в поиске— выполнение запроса было прервано из-за превышения допустимого времени выполнения
Еще одна причина деградации производительности, не связанная напрямую с запросом, — mapping explosion: ситуация, когда индекс содержит слишком большое количество динамически созданных полей. В этом случае медленная работа запроса — следствие проблемы на уровне индекса, а не SML-запроса.
Поэтапная отладка
Поскольку SML-запрос выполняется последовательно, ошибку легче всего найти, проверяя каждый этап конвейера по отдельности. Если написанный запрос не работает или работает не так, как ожидалось, стоит воспользоваться методом последовательного наращивания логики.
- Валидация источника
Первоначальный этап диагностики заключается в проверке доступности данных в выбранном источнике и временном интервале. Для этого выполняется базовая команда source без дополнительных фильтров и преобразований:
source nginx-logs-*
При отсутствии результатов следует проверить корректность имени индекса (паттерна) и настройки временного диапазона поиска.
- Метод последовательного наращивания конвейера
Локализация ошибки достигается путем поочередного добавления команд в запрос. Проверка промежуточного результата осуществляется после каждого нового этапа:
-
фильтрация и первичный отбор (
search,where). Проверяется точность вхождения событий в выборку. Ошибки на этом уровне приводят к пустому результату или избыточности данных -
извлечение данных из неструктурированных полей (
rex,spath). При работе с логами или JSON проверяется корректность работы регулярных выражений и парсеров. Если поле не извлечено на этом этапе, все последующие команды не смогут к нему обратиться -
преобразование и вычисление полей (
eval/peval,rename). Проверяется корректность математических операций, конкатенации строк, приведения типов и т.д. -
обогащение данных (
lookup,join,append). Проверяется корректность сопоставления с внешними справочниками. На этом этапе выявляются несовпадения в названиях и типах полей в основном потоке и в справочнике -
операции агрегации и расчет статистики (
aggs/stats,timeaggs/timechart). Проверяется правильность группировки и точность функций. Ошибки часто связаны с неверным выбором функции (например,countвместоdc) -
манипуляция набором данных (
dedup,sort,mvexpand). Проверяется корректность изменения структуры набора событий: удаление дублей, сортировка или развертывание многозначных полей -
финальное форматирование (
table,fields). На последнем этапе проверяется состав возвращаемых данных
Если на определенном этапе запрос перестает корректно работать, то это позволяет однозначно определить проблемную команду.
- Использование комментариев для изоляции блоков
Для временного исключения частей запроса без их удаления применяются многострочные комментарии /* ... */. Это позволяет ограничить выполнение запроса определенными командами:
source internal_audit-*
| search status="error"
/* | eval error_code = upper(code)
| aggs count by error_code
*/
В данном примере выполнение завершится после команды search, что позволит увидеть промежуточный набор событий.
- Ограничение результатов запроса
При работе с большим числом полей с целью отладки значений только в определенных из них рекомендуется ограничивать набор полей командами fields и table.
source users
| peval full_name = first_name + " " + last_name
| table @timestamp, first_name, last_name, full_name
Статистика запроса
Smart Monitor позволяет проанализировать статистику выполненного запроса. Для отображения статистики запроса необходимо выбрать режим отображения статистики (INFO или DEBUG) и нажать на строку со сводной информацией о количестве найденных документов и времени выполнения запроса.
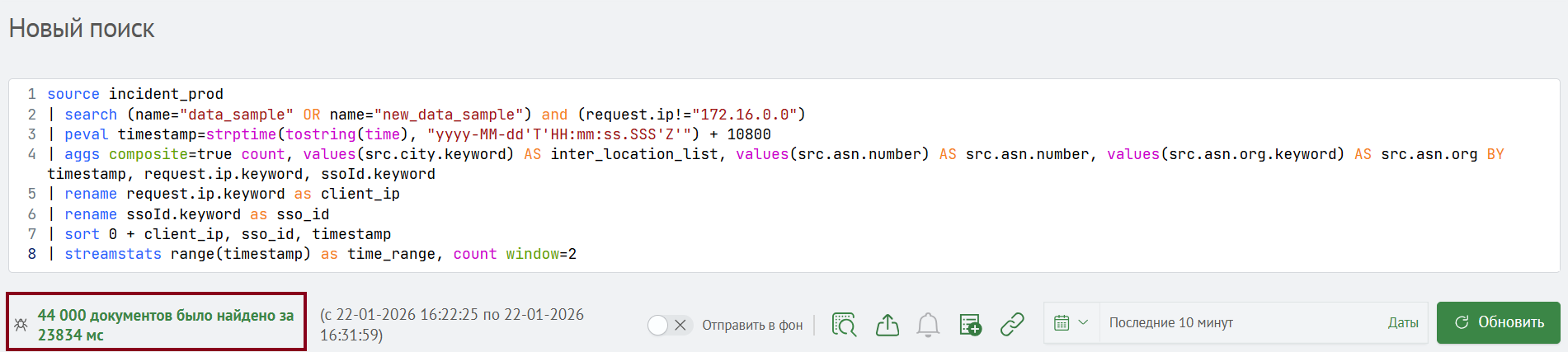
Статистика запроса в режиме DEBUG предоставляет сведения о длительности выполнения команды, типе команды, количестве документов в обработке, размере обрабатываемых документов в мегабайтах и объеме оперативной памяти, выделенной на выполнение команды.

Данная информация помогает понять, на каком этапе происходит замедление выполнения запроса и увеличения использования ресурсов.
Режим INFO используется для общей оценки хода выполнения поиска, обеспечивая меньшую степень детализации данных по сравнению с расширенным режимом DEBUG.
Мониторинг производительности запросов
Модуль Самомониторинг предоставляет дашборд "Мониторинг производительности запросов" с информативными визуализациями о фазах и эффективности выполнения запросов. На основе этих данных можно оценить работу запросов в Smart Monitor.
