Painless-скрипты
Painless — это встроенный язык скриптов, разработанный для безопасного, быстрого и удобного исполнения пользовательских вычислений прямо внутри поискового движка. В отличие от более общих языков (Groovy, JavaScript или Python), Painless оптимизирован под задачи обработки и агрегации данных в реальном времени: он компилируется в байт-код JVM, поддерживает строгую типизацию и жесткие ограничения безопасности (sandbox), что снижает риск выполнения потенциально опасного кода.
В данной статье рассматривается синтаксис Painless, способы его интеграции в запросы и агрегации, а также приводятся практические примеры использования Painless-скриптов.
Основы синтаксиса Painless
Painless использует знакомые из Java конструкции, обеспечивая при этом безопасность и высокую производительность. Скрипты состоят из объявлений переменных, арифметических и логических выражений, управляющих конструкций и взаимодействия с документами и параметрами.
Объявление переменных и типы данных
При работе со скриптом сразу создаются переменные и задаются типы, к примеру:
// Примитивы
int count = 0;
long hits = doc['views'].value;
double price = params.basePrice;
// Ссылочные типы и автоматический вывод типа
String status = 'new';
List tags = new ArrayList();
Map extras = params;
def total = price * params.markup;
Операторы и выражения
Painless поддерживает привычные арифметические (+, -, *, /, %), логические (&&, ||, !) и сравнительные (==, !=, <, >, <=, >=) операторы. Для простых условий удобно использовать тернарный оператор:
// Если балл аномалии выше порога — пометить как критический
def status = anomalyHits > params.criticalThreshold ? 'CRITICAL' : 'NORMAL';
Управляющие конструкции
Полноценные if/else и циклы (for, while) позволяют реализовать логику прямо в запросах и обновлениях:
// Условная логика при обновлении документа
if (ctx._source.login_failures > params.maxFailures) {
ctx._source.account_status = 'locked';
} else {
ctx._source.account_status = 'active';
}
// Цикл по индексированным значениям
for (int i = 0; i < items.size(); i++) {
ctx._source.total += items.get(i);
}
// for-each для коллекций
for (def tag : tags) {
ctx._source.tags.add(tag.toLowerCase());
}
Работа с документом и параметрами
В Painless можно обращаться к параметрам скрипта через объект params, к хранимым в документе полям — через doc['field'].value, а при обновлении — изменять исходный документ через ctx._source.
// Чтение времени события и вычисление задержки обработки
def eventTime = doc['@timestamp'].value.toInstant().toEpochMilli();
def currentTime = params.nowMillis;
ctx._source.latencyMs = currentTime - eventTime;
// Фильтрация по пользователю и обновление счетчика
if (params.userName == doc['user.name.keyword'].value) {
ctx._source.userEventCount = doc['user.eventCount'].value + 1;
}
Хранимые скрипты и повторное использование
Для централизованного хранения и повторного использования Painless-скрипты можно сохранять в кластере:
PUT _scripts/calc_tax
{
"script": {
"lang": "painless",
"source": """
double rate = params.rate;
return params.amount * (1 + rate);
"""
}
}
Команда PUT _scripts/<script_id> регистрирует скрипт в кластере и присваивает ему уникальный идентификатор.
Хранимые скрипты удобно использовать в различных сценариях: для вычисления значений, сортировки, фильтрации, агрегации и обновления документов. При выполнении запросов достаточно указать его id и передать необходимые параметры:
GET products/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"price_with_tax": {
"script": {
"id": "calc_tax",
"params": {
"amount": 120,
"rate": 0.18
}
}
}
}
}
В приведенном примере используется хранимый скрипт calc_tax. В запросе выполняется простая фильтрация через match_all. В разделе script_fields создается новое поле price_with_tax, вычисляемое по скрипту.
Эти механизмы Painless позволяют писать скрипты для фильтрации, сортировки, агрегации и обновления данных в Smart Monitor.
Painless-скрипты в Smart Monitor
Управление Painless-скриптами в Smart Monitor доступно в разделе Навигационное меню - Параметры системы - Настройки модулей — Основное — Painless-скрипты.
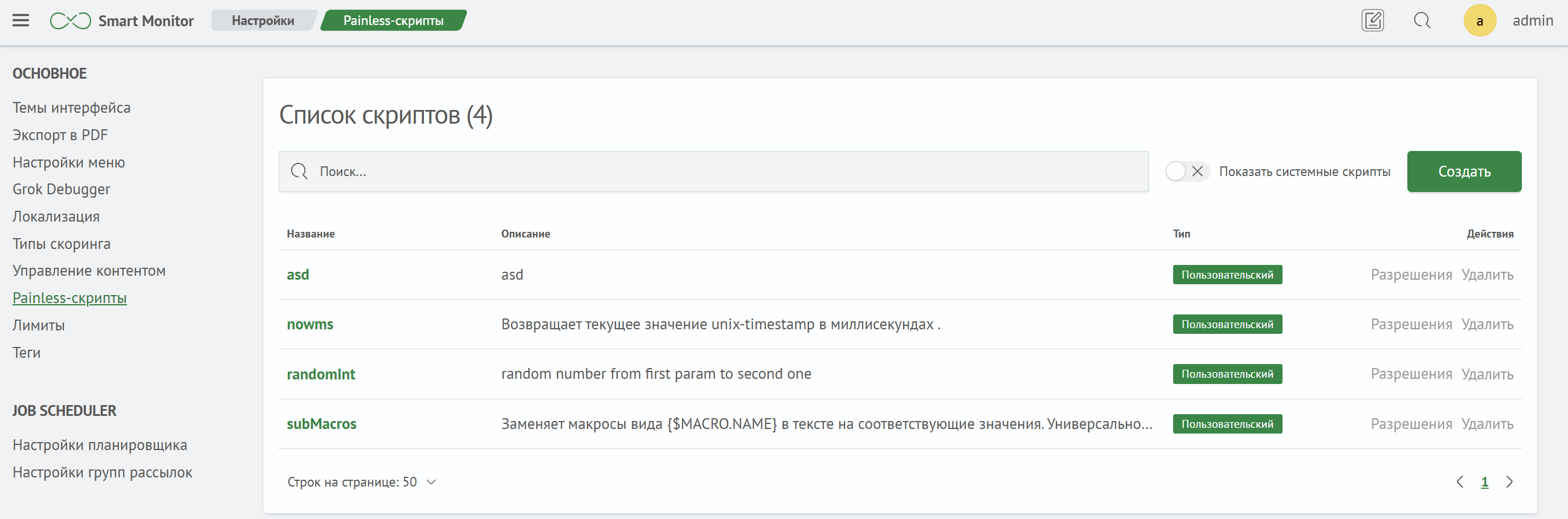
В интерфейсе представлен список созданных Painless-скриптов.
Помимо пользовательских скриптов в интерфейсе возможно отображение и системных скриптов. Для этого необходимо сделать активной кнопку Показать системные скрипты. Системные скрипты имеют тип internal. В полученном списке можно найти интересующую функцию и подробнее изучить ее особенности.
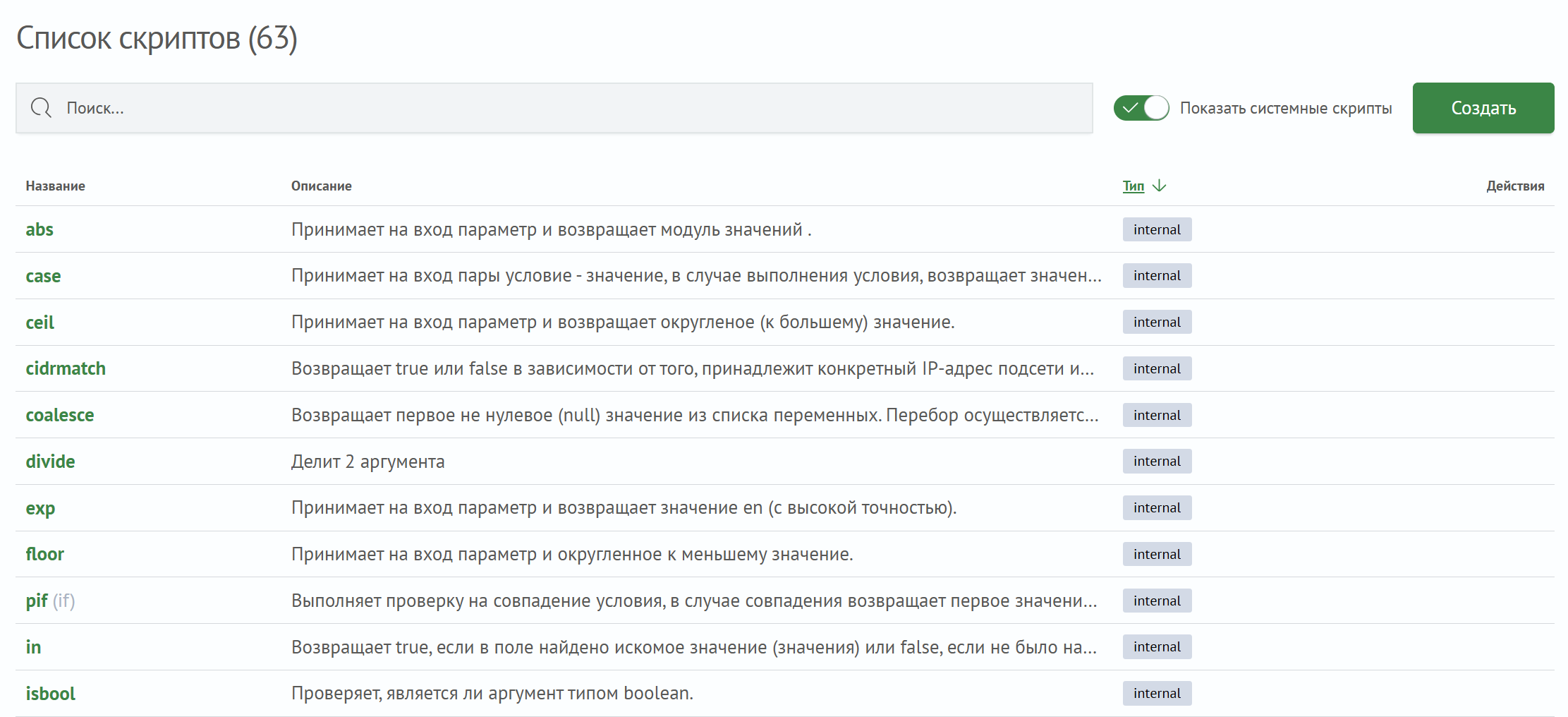
Системные скрипты невозможно удалить и отредактировать.
Создание Painless-скриптов
Для создания нового Painless-скрипта необходимо
-
Нажать кнопку
Создать -
Заполнить поля в редакторе
-
Нажать кнопку
Сохранитьв форме редактирования
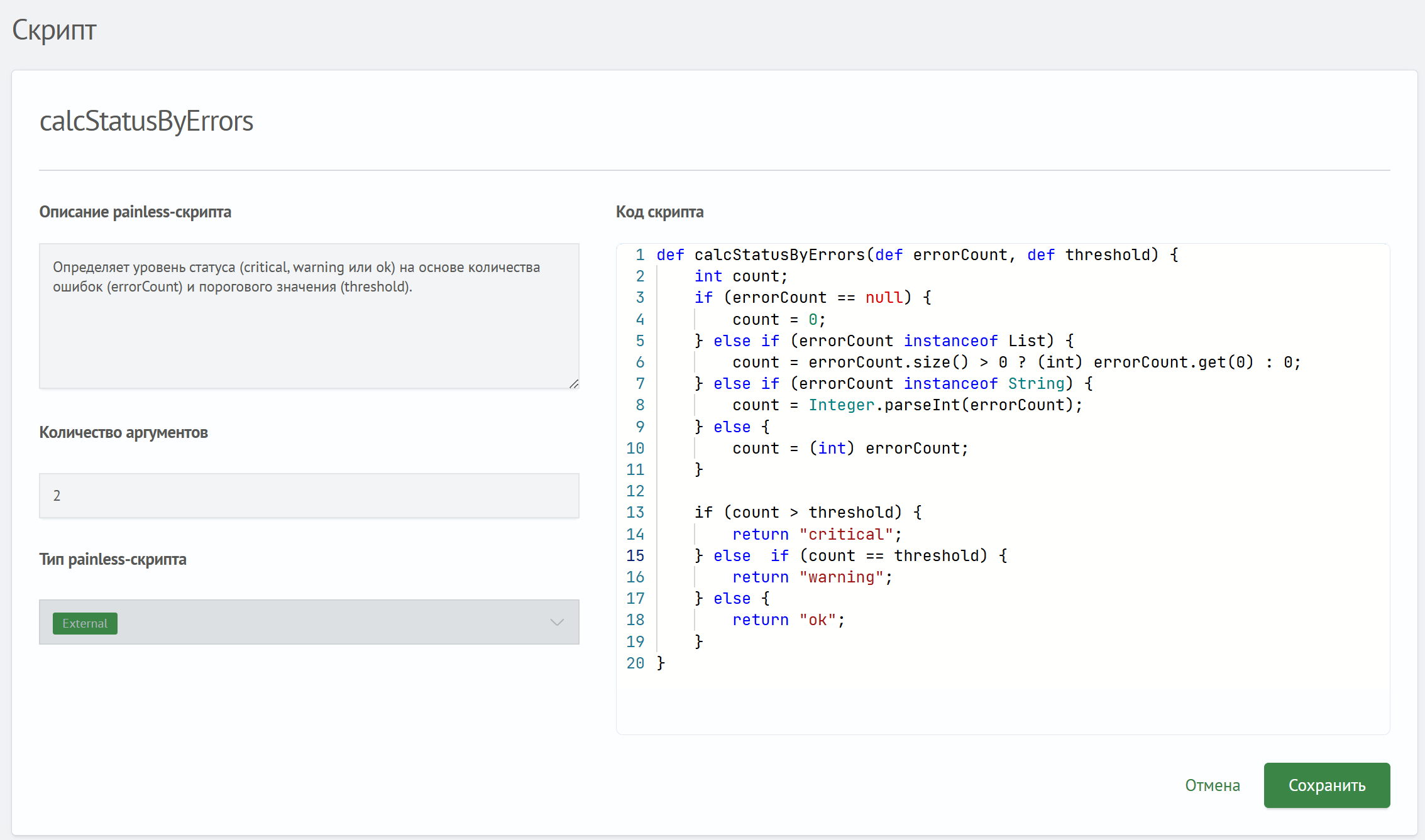
Редактор скриптов состоит из пяти секций:
Название функции— название, через которое можно вызвать скрипт в поисковых запросахОписание painless-скрипта— описание функциональности painless-скриптаКод скрипта— скрипт на языке PainlessКоличество аргументов— число аргументов, которое принимает функцияТип painless-скрипта— отображаемый в списке скриптов тег
Созданные Painless-скрипты сохраняются в системный индекс .sm_sme_scripts.
Интеграция Painless-скриптов в запросы
Созданные в Smart Monitor скрипты можно использовать непосредственно в поисковых запросах с помощью команды peval.
К примеру, можно вызвать скрипт calcStatusByErrors, который определяет уровень статуса на основе количества ошибок и порогового значения для каждого документа.
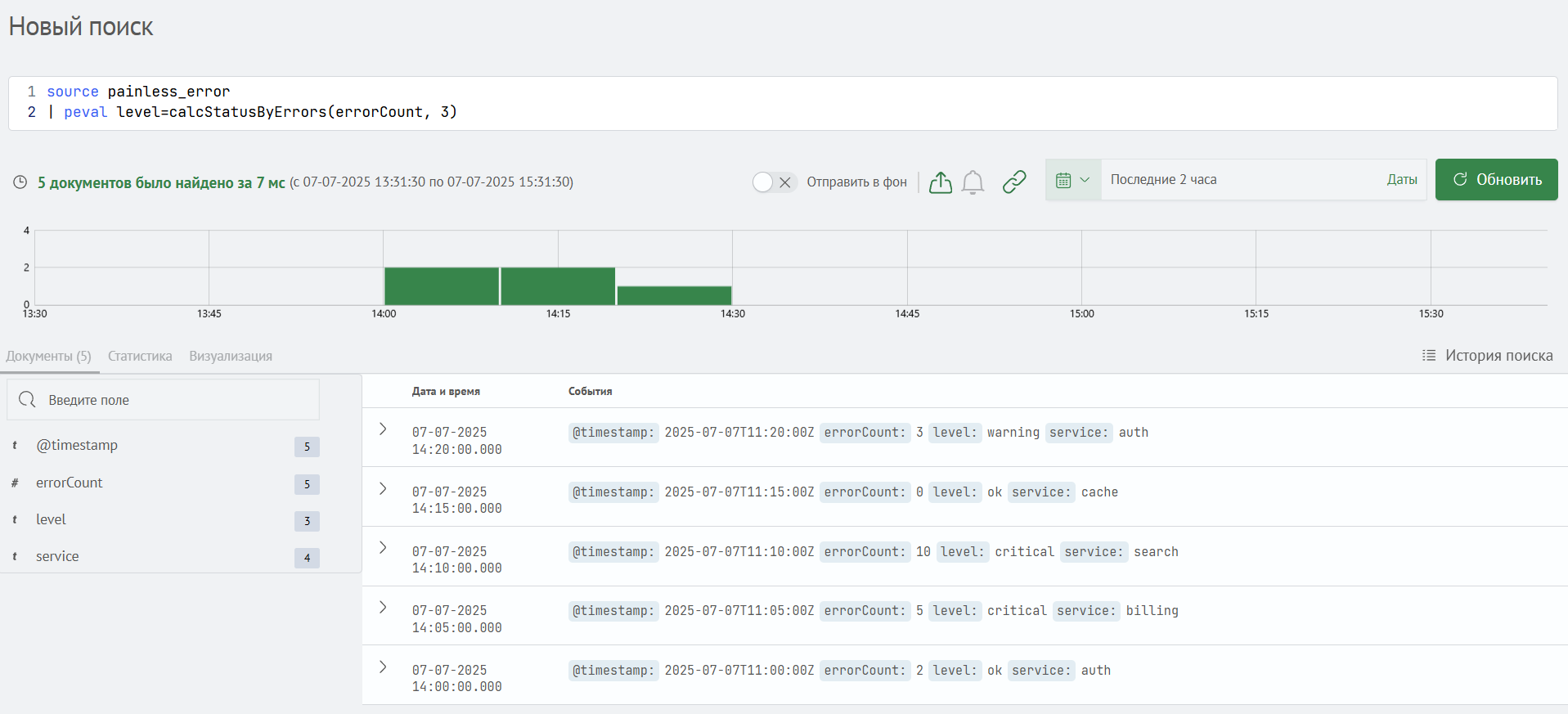
В результате выполнения запроса уровень статуса level корректно определился для всех найденных документов.
Механизмы применения Painless-скриптов
При работе с Painless-скриптами можно применять специальные механизмы, позволяющие создавать дополнительные поля во время выполнения запроса, задавать собственные формулы ранжирования и автоматически править тысячи документов за один запрос.
Рассмотрим основные механизмы при интеграции Painless-скриптов в запросы.
- Виртуальные поля через script_fields
В теле запроса поиска можно задать секцию "script_fields", в которой указываются имена виртуальных полей и соответствующие им Painless-скрипты. Эти скрипты выполняются для каждого документа во время поиска, а сами документы при этом не изменяются.
GET /my_index/_search
{
"_source": ["timestamp","eventType","metricValue"],
"script_fields": {
"level": {
"script": {
"lang": "painless",
"source": """
// вычисляемый уровень: 'HIGH' если значение превышает порог, иначе 'LOW'
return doc['metricValue'].value > params.threshold
? 'HIGH'
: 'LOW';
""",
"params": { "threshold": 100 }
}
}
},
"query": { "match_all": {} }
}
В результате выполнения данной команды к каждому найденному документу в разделе fields.level добавится значение HIGH, если поле metricValue больше 100, или, в противном случае, LOW. Исходные данные в индексе при этом не меняются. Ключ fields формируется поисковым движком и содержит хранимые результаты всех script_fields. Имя level в fields.level соответствует названию поля в запросе — script_fields.level.
- Собственный расчет _score через script_score
Встроенный расчет метрики _score, определяющей порядок найденных результатов, можно заменить или дополнить пользовательской формулой. Для этого внутри function_score используется секция script_score.
GET /my_index/_search
{
"query": {
"function_score": {
"query": { "match": { "eventType": "authentication" } },
"script_score": {
"script": {
"lang": "painless",
"source": """
// базовая оценка + 0.5 балла за каждую ошибку
double base = params.baseScore;
int errs = doc['errorCount'].value;
return base + errs * params.errorWeight;
""",
"params": {
"baseScore": 1.0,
"errorWeight": 0.5
}
}
}
}
}
}
В приведенном примере каждый документ, где eventType равно "authentication", получит значение _score, вычисленное как 1.0 + errorCount × 0.5. Сортировка результатов будет выполнена по новому _score.
- Массовое обновление через update_by_query
Метод update_by_query позволяет применить Painless-скрипт ко всем документам, удовлетворяющим заданному условию, и сохранить изменения в индекс. Это удобно при необходимости массово обновить поле, выставить метки или скорректировать данные без загрузки и обработки документов вручную.
POST /my_index/_update_by_query
{
"query": {
"term": { "status": "pending" }
},
"script": {
"lang": "painless",
"source": """
// получаем текущий счетчик (или инициализируем)
int cnt = ctx._source.processedCount != null
? ctx._source.processedCount + 1
: 1;
ctx._source.processedCount = cnt;
// если более трех обработок — помечаем для проверки
if (cnt > params.max) {
ctx._source.flag = 'review';
}
""",
"params": { "max": 3 }
}
}
В результате выполнения данной команды все документы со status = "pending" будут обновлены: поле processedCount увеличится на 1 (или будет установлено в 1, если ранее отсутствовало), а при значении более 3 в поле flag запишется 'review'.
- Фильтрация и сортировка с использованием скриптов
Painless-скрипты можно использовать в запросах, чтобы задавать гибкие условия фильтрации и сортировки. Это удобно, когда нужно учитывать не только значение поля, но и дополнительные параметры, преобразования или формулы.
GET /my_index/_search
{
"query": {
"script": {
"script": {
"lang": "painless",
"source": "doc['metricValue'].value * params.coeff > params.threshold",
"params": {
"coeff": 1.2,
"threshold": 100
}
}
}
}
}
В приведенном примере возвращаются только те документы, у которых metricValue, умноженное на коэффициент 1.2, превышает 100. Такая фильтрация удобна, когда условие зависит от параметров, а не от конкретного значения поля.
- Агрегации с использованием скриптов
Painless-скрипты могут использоваться в агрегациях, например:
- для вычисления значения на основе нескольких метрик
- для объединения значений
- для динамического деления по группам
Пример: динамическая группировка документов на основе вычисляемого условия, заданного скриптом.
GET /my_index/_search
{
"size": 0,
"aggs": {
"dynamic_groups": {
"terms": {
"script": {
"lang": "painless",
"source": """
return doc['metricValue'].value > 100 ? "high" : "low";
"""
}
}
}
}
}
Результатом будет агрегация по двум группам: "high" и "low", определяемым логикой скрипта, а не фиксированным значением поля.
- Трансформация «на входе» через ingest‑pipeline
При использовании ingest‑pipeline Painless-скрипты выполняются еще до сохранения документа в индекс. Это позволяет обогащать или нормализовать поля во время выполнения запроса.
PUT _ingest/pipeline/normalize-metric
{
"description": "Нормализация metricValue к диапазону 0–1",
"processors": [
{
"script": {
"lang": "painless",
"source": """
// если metricValue есть — делим на максимум 200, иначе 0
def v = ctx.metricValue != null ? ctx.metricValue : 0;
ctx.metricValueNorm = v / 200;
"""
}
}
]
}
Когда документ отправляется в индекс с указанием конвейера normalize-metric, скрипт в этом конвейере нормализует значение metricValue, добавляя к документу новое поле metricValueNorm.
POST /my_index/_doc?pipeline=normalize-metric
{ "metricValue": 150, "eventType": "login" }
В приведенном примере результатом станет metricValueNorm: 0.75:
Все методы ingest, доступные в Painless, ограничены пространством имен Processors.
- Поля во время выполнения (runtime fields)
Runtime‑поля прописываются в mappings индекса и при каждом запросе вычисляются Painless‑скриптом в момент выполнения запроса. В отличие от script_fields, для их использования не нужно каждый раз включать скрипт в тело запроса — они сразу присутствуют в схеме и доступны в условиях фильтрации, агрегациях и сортировке.
PUT /my_index
{
"mappings": {
"runtime": {
"level": {
"type": "keyword",
"script": {
"lang": "painless",
"source": """
// уровень 'high' если metricValue > 100, иначе 'low'
emit(doc['metricValue'].value > params.threshold
? 'high'
: 'low');
""",
"params": { "threshold": 100 }
}
}
}
}
}
После этого поле level можно сразу использовать в запросах:
GET /my_index/_search
{
"query": {
"term": { "level": "high" }
}
}
Отладка Painless‑скриптов
Отладка Painless-скриптов проводится для выявления и устранения ошибок, проверки корректности логики и оценки производительности кода до его внедрения в рабочие процессы.
Execute API
Execute API (POST /_scripts/painless/_execute) позволяет выполнять произвольные Painless‑скрипты независимо от индекса и данных. С его помощью можно:
- быстро проверить синтаксис и базовую логику кода
- убедиться, что выражения возвращают ожидаемые значения
- смоделировать разные контексты (фильтрация, скоринг, агрегации, обновление) до интеграции в реальные запросы
Общая структура запроса выглядит следующим образом:
POST /_scripts/painless/_execute
{
"context": "<название_контекста>",
"context_setup": {
"index": "<имя_индекса>",
"document": { /* пример документа */}
},
"script": {
"lang": "painless",
"source": "<код_скрипта>",
"params": { /* параметры */ }
}
}
context— окружение, в котором выполняется скриптcontext_setup— используется для задания тестового окружения: индекса и документа, с которым будет работать скрипт. Это необходимо при использованииdoc['field']иctx._sourcescript.source— пользовательский Painless‑кодparams— объект, содержащий пользовательские параметры, передаваемые в скрипт из запроса
В некоторых сценариях могут использоваться расширенные параметры, такие как query — для передачи условий в скриптах с контекстом score или emit — для вывода значений в runtime-полях.
Параметр context_setup обязателен для всех контекстов, кроме painless_test. Он задает тестовый индекс и документ, необходимые для корректного моделирования выполнения скрипта.
Если context не указан, по умолчанию используется painless_test.
Доступные контексты представлены в таблице ниже:
| Контекст | Доступные объекты | Назначение |
|---|---|---|
| painless_test | params | базовое тестирование арифметики и логики |
| filter | doc, params | проверка условий фильтрации |
| score | doc, params, _score | тестирование script_score |
Ниже приведен пример запуска Execute API в контексте проверки фильтрации. Скрипт должен вернуть true, если поле metricValue тестового документа превышает заданный порог.
POST /_scripts/painless/_execute
{
"context": "filter",
"context_setup": {
"index": "my_index",
"document": {
"metricValue": 120
}
},
"script": {
"source": "doc['metricValue'].value > params.threshold;",
"params": {
"threshold": 100
}
}
}
В результате выполнения этого запроса в ответе появится:
{
"result": true
}
Поле result: true подтверждает, что условие скрипта (metricValue > 100) верно для переданного документа.
Контекстная отладка с помощью Debug.explain()
Когда при тестировании нужно узнать не только результат скрипта, но и внутреннюю структуру объектов (ctx._source, doc, params и т. д.), помогает специальная функция Debug.explain(). Она генерирует ScriptException, в тексте которого содержатся:
- сериализованное (JSON‑подобное) представление указанного объекта
- информация о классе объекта (например,
java.util.LinkedHashMapдля_source) - стек вызова скрипта — список строк, отражающих путь выполнения и указывающих, на какой строке скрипта было вызвано
Debug.explain(). Это помогает точно определить местоположение и контекст вызова отладочной функции
Пример выполнения запроса с Debug.explain():
POST /my_index/_update/1
{
"script": {
"lang": "painless",
"source": "Debug.explain(ctx._source);"
}
}
В результате выполнения запроса скрипт сразу же генерирует исключение, содержащее строковое представление объекта _source, включая его поля, значения и тип данных. Это позволяет убедиться, какие данные доступны внутри скрипта, и как именно они представлены. Такой прием особенно полезен при работе с вложенными объектами или динамически меняющимися схемами документов.
Пример фрагмента ошибки:
{
"error": {
"root_cause": [
{
"type": "script_exception",
"reason": "RuntimeException[LinkedHashMap] {user=alice, count=5}"
}
],
"script_stack": [
"Debug.explain(ctx._source);",
" ^---- HERE"
],
...
}
}
Приведенный фрагмент ошибки демонстрирует результат работы Debug.explain(ctx._source). В поле reason видно сериализованное содержимое объекта _source: это LinkedHashMap с полями user=alice и count=5, что подтверждает наличие этих данных в документе. Также указывается тип объекта (LinkedHashMap), что важно при диагностике проблем с обращением к полям — особенно если возникает ошибка типов или попытка обратиться к несуществующему ключу.
В script_stack отображается строка скрипта, вызвавшая исключение, и точка, в которой оно было сгенерировано. Это помогает быстро локализовать отладочный вызов внутри большого скрипта.