Статистика
Вычисляет статистику о действиях объекта за промежуток времени. Используется для обнаружения аномалий, таких как:
- число подключений к VPN за 20 минут, превысило стандартные показатели для пользователя
- пользователь отправил необычно большой объем писем за час
Описание алгоритма
- К данным индексов источников применяется общий и временной фильтры
- Данные разбиваются на интервалы
- Для поля или результата выполнения скрипта на каждом интервале вычисляется функция агрегации, указанная в настройках алгоритма. В целом получается массив чисел, где каждое число это результат функции агрегации для данных в интервале
- Вычисляется статистика для массива, полученного на предыдущем шаге
Входные параметры
-
Фильтр - общий фильтр источников (используются выражения из команды search)
-
Индекс для результатов - индекс в который записываются результаты выполнения
-
Интервал - величина промежутков времени на которые разделяются данные источников. (Примеры заполнения:
1y- год,1M- месяц,1d- день,1H- час,1m- минута,1s- секунда) -
Пропускать интервалы без данных - пустые интервалы не учитываются в расчете статистики
-
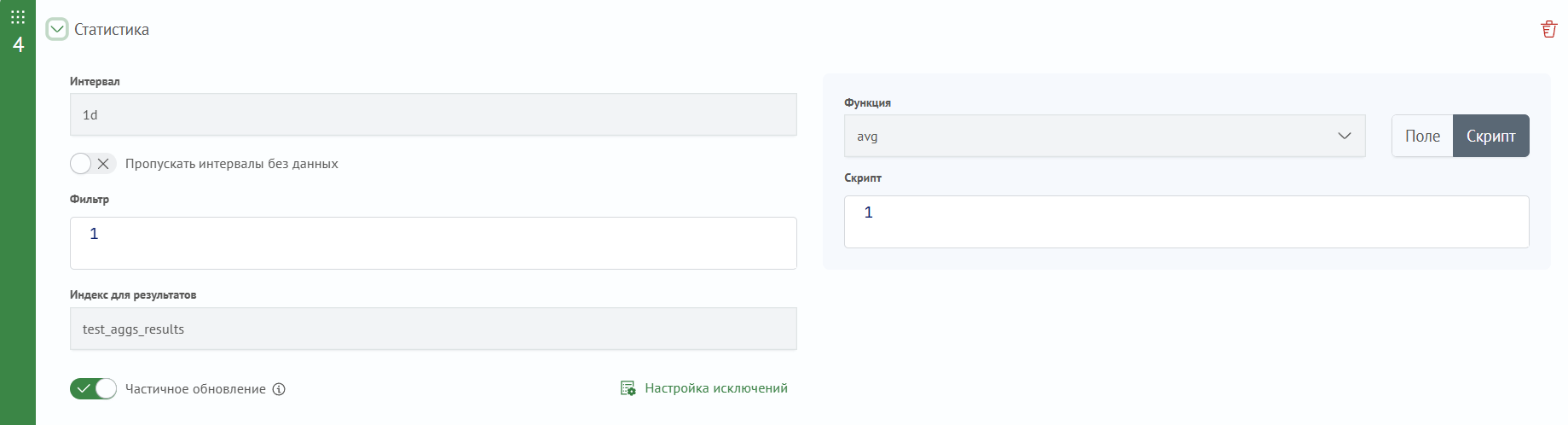
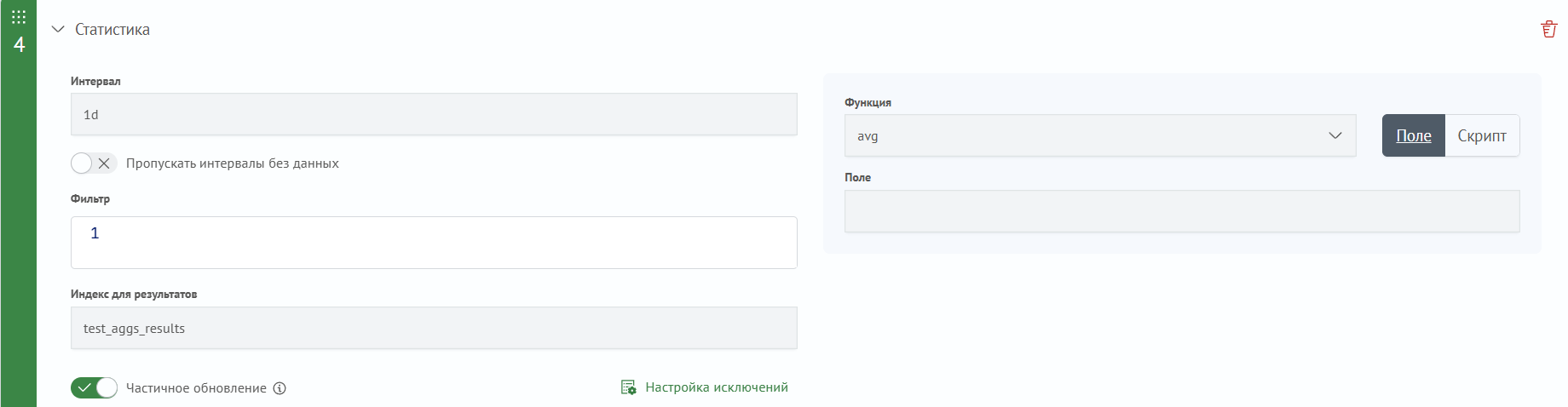
Функция - функция агрегации. Одна из функций:
sum- суммаmin- минимальноеmax- максимальноеavg- среднееdc- количество уникальных значенийcount- количество событий в интервале
-
Скрипт - painless-скрипт для вычисления числового значения аргумента функции
-
Поле - название числового поля источника данных, значение которого будет использоваться как аргумент функции
-
Частичное обновление - позволяет выбрать режим обновления данных:
- Если выключено - при каждом запуске старые данные будут очищаться, загружая только новые значения
- Если включено - старые данные будут сохраняться и дополняться новыми значениями, обогащая уже накопленные записи
примечаниеВ режиме
частичного обновленияперерасчету подлежат только значенияpercentilesи базовые метрики изextended_stats(min,max,sum,count,avg). Остальные агрегатыextended_statsне обновляются.Обратите внимание, что в этом режиме нельзя провести расчёт по функции
dc. -
Настройка исключений - предоставляет возможность указать правила исключений данных из расчета. При нажатии открывается модальное окно, в котором можно добавить условия для исключения отдельных объектов.
Входные данные
Входные данные определяются индексами и временным интервалом в общих настройках.
Выходные данные
В результате выполнения алгоритма результирующий индекс содержит структурированные статистические данные для заданных настроек:
_meta.calculation.id- идентификатор настройки алгоритма в политике профилирования_meta.calculation.type- тип алгоритма_meta.execution.start_time- время запуска политики профилирования_meta.execution.id- идентификатор запуска политики профилирования_meta.object.identity- массив идентификаторов UBA объекта_meta.object.id- технический идентификатор UBA объекта_calculation- результат выполнения алгоритма_calculation.extended_stats- расширенная статистика по всем интервалам_calculation.percentiles- процентиль по всем интервалам_calculation.span- величина интервала
Пример json-объекта результата
{
"_index": "test-aggs-result",
"_id": "_pOmmI4BtwOJADfCzSjL",
"_score": 8.713484,
"_source": {
"_meta": {
"calculation": {
"id": "1phiQY4BEuHUnGrO6ufe",
"type": "aggregation"
},
"execution": {
"start_time": "2025-04-04T09:57:09.096Z",
"id": "-ZOmmI4BtwOJADfCzShr"
},
"object": {
"identity": [
"romanov.a@volgablob.ru",
"89166788776",
"romanov.a"
],
"id": "9186db972bafeafed6411ab644d0313bb1def204"
}
},
"_calculation": {
"extended_stats": {
"count": 2,
"min": 5,
"max": 5,
"avg": 5,
"sum": 10,
"sum_of_squares": 50,
"variance": 0,
"variance_population": 0,
"variance_sampling": 0,
"std_deviation": 0,
"std_deviation_population": 0,
"std_deviation_sampling": 0,
"std_deviation_bounds": {
"upper": 5,
"lower": 5,
"upper_population": 5,
"lower_population": 5,
"upper_sampling": 5,
"lower_sampling": 5
}
},
"percentiles": {
"values": {
"1.0": 5,
"5.0": 5,
"25.0": 5,
"50.0": 5,
"75.0": 5,
"95.0": 5,
"99.0": 5
}
},
"last_timestamp": "2025-04-04T09:57:09.096Z",
"span": "1d"
}
}
}