Преобразование полей с множественными значениями
Поле с множественными значениями (многозначное поле) — это поле, которое содержит более одного значения. Например, журнал электронной почты имеет многозначные поля «Кому:», «Копия:», или журнал интернет-магазина содержит поле со списком товаров.
Ниже представлены основные команды для работы с многозначными полями.
mvappend
Объединение полей.
Запрос создаст поле event_info, которое соберёт в себе информацию нескольких других полей. Количество параметров, подаваемых в функцию mvappend может иметь различное число, отличных от нуля.
source sm_cs_auth_indexes
| table user.name, source.ip, event.action
| eval event_info = mvappend(user.name, source.ip, event.action)

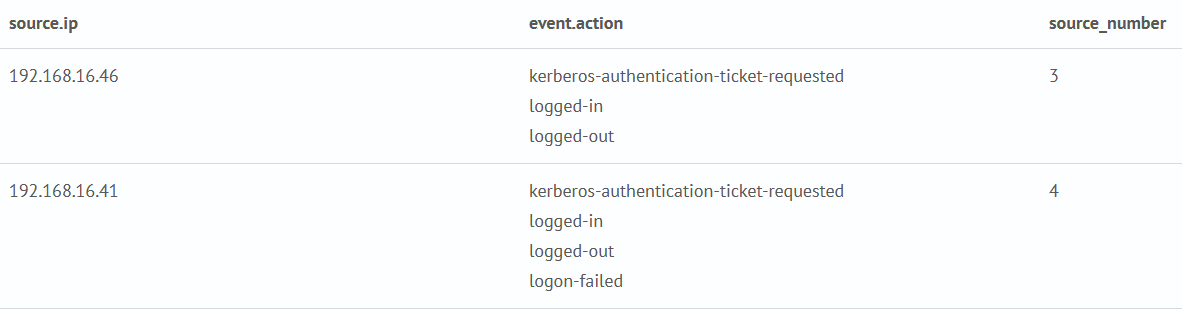
mvcount
Подсчет количества значений многозначных полей.
Как и в случае атомарных значений полей, многозначные поля также можно посчитать. Для этого существует команда mvcount.
Запрос создаст список событий поля event.action группируя по полю source.ip, а далее выполняется команда mvcount которая считает количество значений в поле event.action.
source sm_cs_auth_indexes
| stats values(event.action) as event.action by source.ip
| eval source_number = mvcount(event.action)
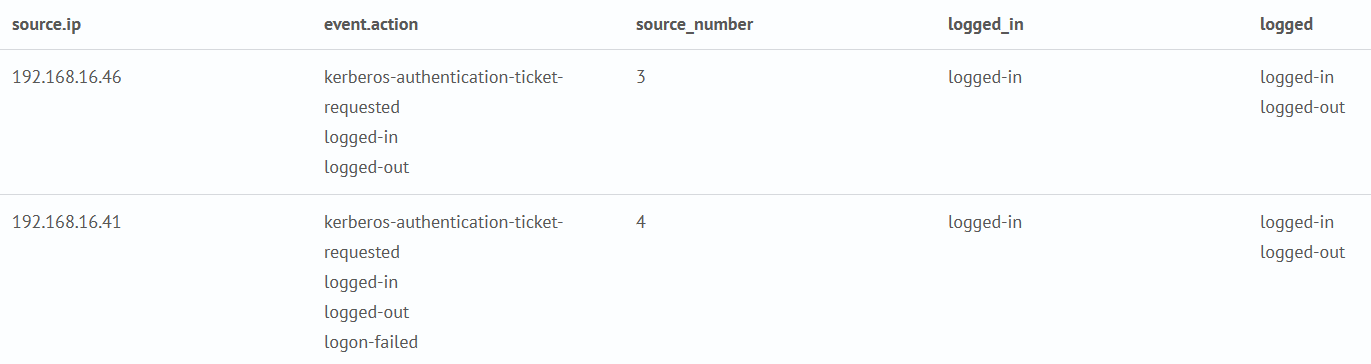
mvfilter
Фильтрация многозначных полей.
Запрос создаст новые поля logged_in и logged, используя функции mvfilter и match, которые помогут выделить согласно шаблонам нужные значение в поле event.action. Внутри команды mvfilter используются различные функции совпадений (например, match, cidrmatch, in и т.д.).
source sm_cs_auth_indexes
| stats values(event.action) as event.action by source.ip
| eval source_number = mvcount(event.action)
| eval logged_in = mvfilter(match(event.action, "logged-in"))
| eval logged = mvfilter(match(event.action, "logged-(.*)"))
mvjoin
Принимает на вход имя многозначного поля, значение конкатенатора и возвращает строку со всеми значениями через конкатенатор.
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id), далее выполняет конкатенацию значений поля product (список продуктов в заказе) с использованием конкатенатора ",".
При выводе таблицы выполнится сортировка выводимых значений. В столбце product выполнена сортировка значений. В столбце result действительный порядок значений в поле product. Действительный порядок значений важен при работе с индексами значений. Поэтому, рекомендуется использовать сортировку значений полей при помощи команды mvsort.
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval result=mvjoin(product, ", ")
| table user_id, product, result

mvsort
Принимает имя многозначного поля и выполняет внутри него сортировку.
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id), далее выполняет сортировку (mvsort) значений внутри поля product (список продуктов в заказе), далее выполняет конкатенацию значений поля product (список продуктов в заказе) с использованием конкатенатора ", ".
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval product=mvsort(product)
| eval result=mvjoin(product, ", ")
| table user_id, product, result

mvfind
Принимает на вход параметр и возвращает индекс первого найденного совпадения. Индекс начинается с 0.
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id), далее выполняет сортировку (mvsort) значений внутри поля product (список продуктов в заказе), и возвращает индекс первого найденного совпадения по шаблону "C(.*)" в поле product. Нумерация индексов элементов многозначного поля начинается с нуля.
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval product=mvsort(product)
| eval result=mvfind(product, "C(.*)")
| table result, user_id, product

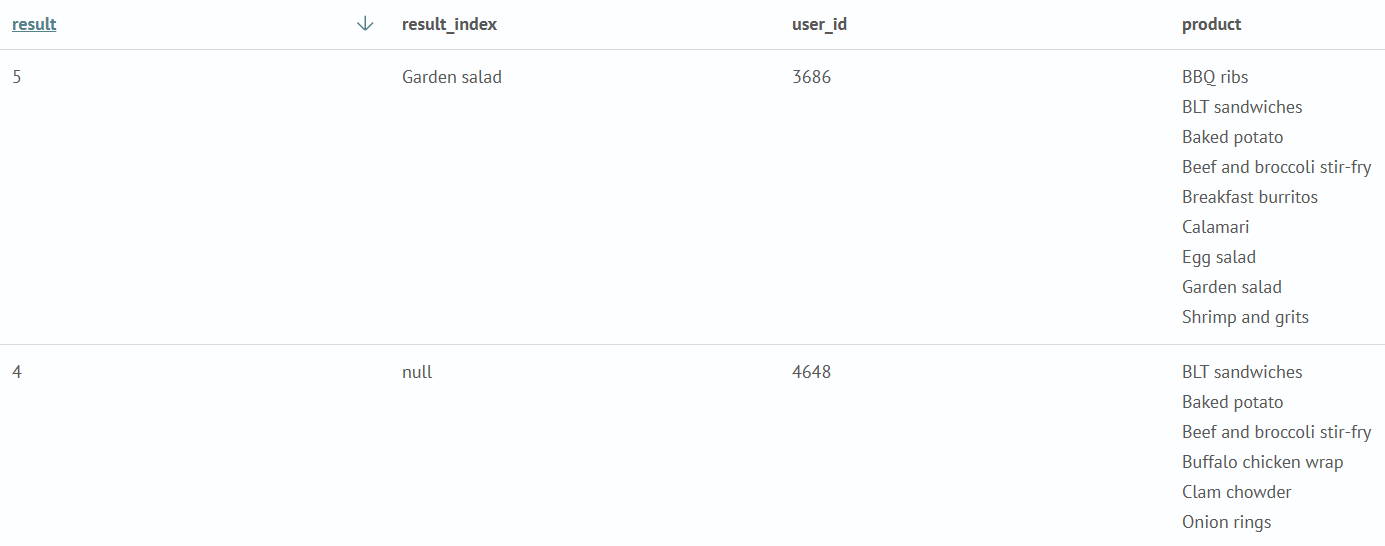
mvindex
Принимает на вход параметр и номер искомого индекса в многозначном поле. Возвращает значение или null, если не найдено.
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id), далее выполняет сортировку (mvsort) значений внутри поля product (список продуктов в заказе), и возвращает индекс первого найденного совпадения по шаблону "C(.*)" в поле product, а полю result_index присваивается значений 7-го элемента поля product.
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval product=mvsort(product)
| eval result=mvfind(product, "C(.*)")
| eval result_index=mvindex(product, 7)
| table result, result_index, user_id, product
mvrange
Принимает на вход параметры начала, конца и интервала инкремента (опционально). Возвращает многозначное поле со списком чисел согласно заданным параметрам
source food_orders qsize=100000
| eval range=mvrange(1,50,1)
| table range

mvzip
Принимает многозначные поля и выполняет конкатенацию (через запятые) значений первого поля со вторым (согласно порядку индексов значений первого поля). Если у одного из многозначных полей значений больше, чем в остальных, конкатенация по этим значениям не будет выполнена.
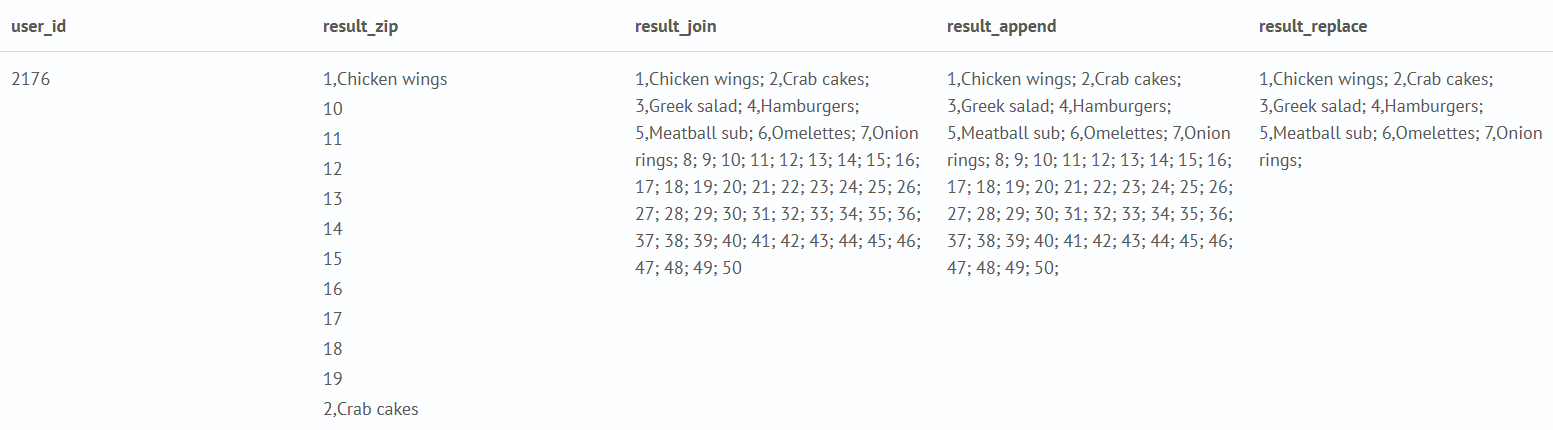
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id), далее выполняет сортировку (mvsort) значений внутри поля product (список продуктов в заказе), затем создается многозначное поле(range) с диапазоном значений от 1 до 50, далее формируется итоговый список(rezult_zip) из значений поля range и product, далее к последнему значению поля result_zip добавляется ";" (поле result_append), далее, так как диапазоны значений полей различаются, удаляются "лишние" номера и получаем итоговый список - поле result_replace.
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval product=mvsort(product)
| eval range=mvrange(1,50,1)
| eval result_zip=mvzip(range,product)
| eval result_join=mvjoin(result_zip, "; ")
| eval result_append=mvappend(result_join + ";")
| eval result_replace = replace(result_append, "[0-9]+;", "")
| table user_id, result_zip, result_join, result_append, result_replace
split
Принимает на вход строку и разделитель. Возвращает многозначное поле, отформатированное с разделителем.
В следующем запросе будут выполнены те же операции, что и в предыдущем, но результирующее поле result_replace будет разделено по шаблону разделителя "; " и выполнена сортировка значений поля result_split .
source food_orders qsize=100000
| stats count, values(items) as product by user_id
| eval product=mvsort(product)
| eval range=mvrange(1,50,1)
| eval result_zip=mvzip(range,product)
| eval result_join=mvjoin(result_zip, "; ")
| eval result_append=mvappend(result_join + ";")
| eval result_replace=replace(result_append, "[0-9]+;", "")
| eval result_split=split(result_replace, "; ")
| eval result_split=mvsort(result_split)
| table user_id, result_zip, result_join, result_append, result_replace, result_split

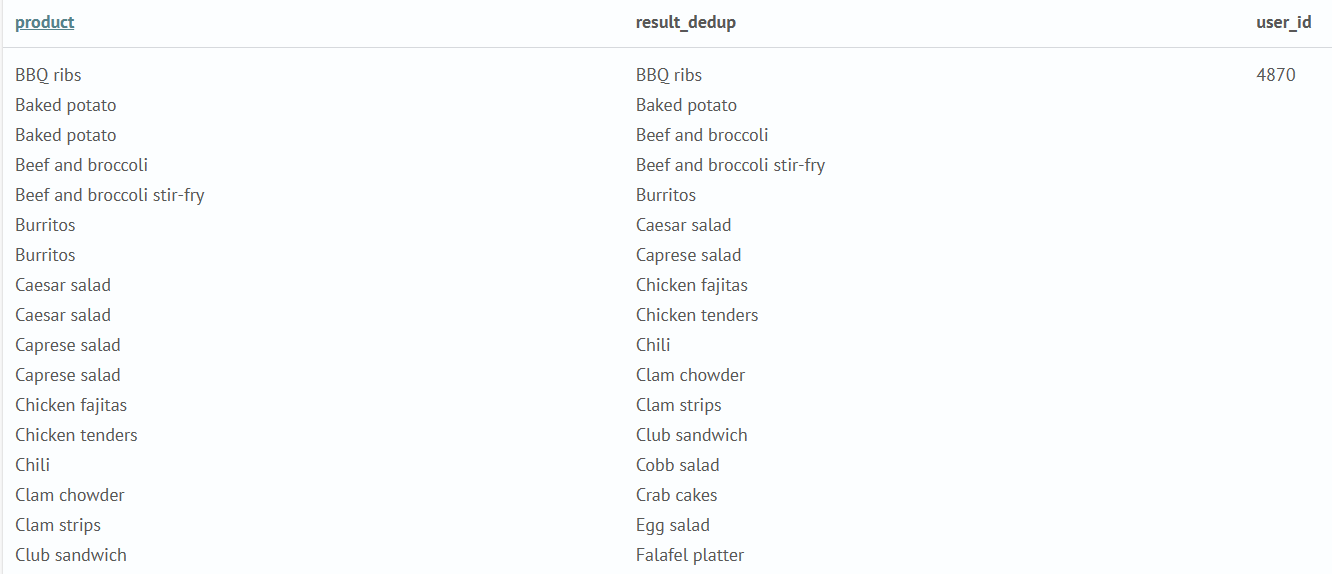
mvdedup
Дедупликация значений в многозначных полях.
Запрос ищет в индексе среди первых 100000 значений число событий (заказов), группируя заказы по идентификатору пользователя (user_id). В отличии от команды values которая сохраняет только уникальные значения в поле, команда list формирует список из всех значений. Поэтому в поле product появятся дубликаты. Команда mvdedup удалит дубликаты значений в поле product, а результат выполнения присвоит полю result_dedup.
source food_orders qsize=100000
| stats count, list(items) as product by user_id
| eval result_dedup=mvdedup(product)
| table product, result_dedup, user_id